
|
Telecom Paris
Dep. Informatique & Réseaux  Nils Holzenberger
← Home pageApril 2026
Nils Holzenberger
← Home pageApril 2026 |

 Logic, Knowledge Representation and Probabilities
Logic, Knowledge Representation and Probabilities
| with | Samuel Reyd |

|
Contents
Introduction to rule-based Natural Language Processing

|
Recommandé:
une petite bande dessinée sur l’I.A. L’Intelligence Artificielle - Fantasmes et Réalités par J.-N. Lafargue et M. Montaigne. |
 |

Brief history of NLP
?- eliza.
Eliza: Oui, vous pouvez tout me dire !
|: j'aime bien faire du python
Eliza: alors vous ne savez pas programmer
|: mais aussi du prolog
Eliza: alors vous savez programmer
|: oui
Eliza: c est un peu court
|: je ne suis pas du genre a parler
Eliza: pourquoi n etes vous pas du genre a parler
|: mon pere non plus n'etait pas du genre a parler
Eliza: dites m en plus sur votre pere
|: non
Eliza: vous etes bien negatif
|: mouais
Eliza: vous n etes pas bavard
|: c'est pas grave
Eliza: hmmm
|: c'est pas grave du tout
Eliza: je ne vous suis pas tres bien
|: c'est pas grave du tout
Eliza: n importe quoi
|: bonsoir
Eliza: merci
You may try it by downloading this Eliza program and by executing ElizaFrench.pl. You may discuss with Eliza and have the kind of interaction shown here. Remember that this version has less than 20 clauses!Admittedly, Eliza is just (a genial) illusion: in English, it just knows how to make an interrogative from an affirmative, and it makes use of a few lexical associations (user- My brother suggested I should chat with you. Eliza- Tell me more about your family). But keep in mind the limited computing power available at that time.Another milestone was the programme SHRDLU, designed by Terry Winograd also in the sixties. This time, the computer had a real understanding of what it was talking about. Shrdlu was amazing, and contrary to Eliza, it did not cheat about its performance. This programme raised great hopes, and then also great disappointment, as it became clear that the method could not scale up. I had the privilege to meet Winograd at Stanford in 1995. I found him quite pessimistic about our ability to bring computers to process meanings as we do. I don’t share this pessimism. In my view, it results from an overestimate of the complexity of the human mind. Considering the mind as unknowable was an understandable reaction to preceding periods in which it had been regarded either as a simple algorithmic machine or as a mere statistical recorder. This debate between rationalism and empiricism has now subsided (for a time). Understanding the human mind (cognitive science), and in particular its language faculty, now goes through standard scientific modelling activity.Machine translation has made much progress (see this gentle introduction to MT (in French)). Admittedly, general purpose translators such those found on the Web (e.g. Babelfish or Systran), though often quite helpful, cannot yet compare with human translation (see Hofstadter’s clever critique on machine translation). But machine translation may be quite efficient for specialized use: a significant proportion of texts written by the European commission are translated into the many official European languages using automated help.Text generation has known a spectacular illustration recently. IBM project debater is able to generate complex argumentations, and the result is impressive: the program is able to take part in debating contests against humans. NLP (Natural Language Processing) has much broader applications than machine translation. It is also commonly used in text proofing, in speech recognition, in dialogue based applications, in optical character recognition, in text mining, in spam filtering, in text generation, in automatic summarization, in speech synthesis, in computer assisted learning, in database indexing and Web search, etc.In 1968, when Stanley Kubrick’s film 2001: a space odyssey was first seen in theatres, people may have doubted whether human beings would be able to travel to Jupiter by the year 2001; however, few would have regarded the spoken dialogue taking place between the astronauts and their smart computer as unrealistic. Such a feat is now considered by engineers to lie still far ahead. It remains, however, an objective rather than a utopia. Few computer scientists would swear that such machines will not be around by the year 2044.
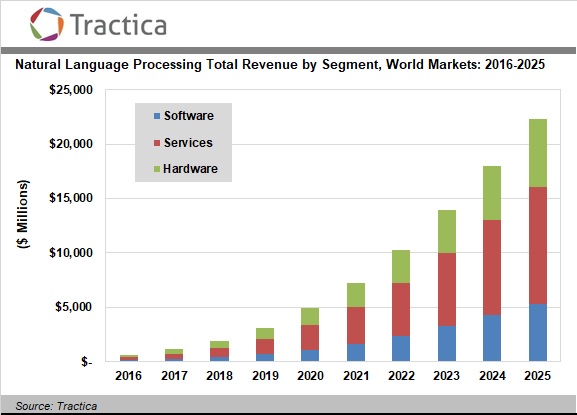 What’s the problem with natural language automation? My opinion about this is that fundamental discoveries are still required at the semantic level (representation of meaning) to lead to realistic implementations. More on this below.The market for NLP is potentially enormous, due to growing demand (more than $20bn according to certain projections). The explosion of NLP business is regularly announced. The current increase, due to quantitative improvements in processing techniques, is rather promising.
What’s the problem with natural language automation? My opinion about this is that fundamental discoveries are still required at the semantic level (representation of meaning) to lead to realistic implementations. More on this below.The market for NLP is potentially enormous, due to growing demand (more than $20bn according to certain projections). The explosion of NLP business is regularly announced. The current increase, due to quantitative improvements in processing techniques, is rather promising.
Two different approaches to NLP
- Symbolic approaches, based on grammars, ontologies, feature structures, unification, logic, cognition ➜ SD213
- Numerical approaches, based on word embedding, machine learning, text mining ➜ SD-TSIA214
Levels of processing
- Acoustic and phonetic processing: convert audio signal into speech sounds
- Phonology: extract phonemes (French has about thirty different phonemes)
- Lexicon: recognize words and morphemes
- Morphology: recognize the internal structure of words (e.g. in French: ‘revalorisées’ = re-+valeur+-iser+-é+-e)
- Syntax: recognize grammatical structure (e.g.: [[John's] sister] [likes [reading [this book [by Kant]]]])
- Semantics: recognise meaning (e.g.: appreciate(marlene,'Kritik der reinen Vernunft'))
- Relevance: understand the relevance in context (e.g.: speaker means that Marlene is smarter that her brother John)
Definite Clause Grammar
| Compared to regular grammars, context-free grammars are: |
| Which automaton is required to analyze sentences, depending on the type of grammar? |
A small grammar
% partial elementary English grammar
% --- grammar
s --> np, vp.
np --> det, n. % Simple noun phrase
np --> np, pp. % Noun phrase + prepositional phrase
np --> [kirk].
vp --> v. % Verb phrase, intransitive verb
vp --> v, np. % Verb phrase, verb + complement: like X
vp --> v, pp. % Verb phrase, verb + indirect complement : think of X
vp --> v, np, pp. % Verb phrase, verb + complement + indirect complement : give X to Y
vp --> v, pp, pp. % Verb phrase, verb + indirect complement + indirect complement : talk to X about Y
pp --> p, np. % prepositional phrase
% -- lexicon
det --> [the]; [my]; [her]; [his]; [a].
det --> [some].
n --> [dog]; [daughter]; [son]; [sister]; [aunt]; [neighbour]; [cousin].
v --> [grumbles]; [likes]; [gives]; [talks]; [annoys]; [hates].
v --> [cries].
p --> [of]; [to].
p --> [about].
This grammar can be tested. Execute family.pl using SWI-Prolog (usually through the command swipl, sometimes pl, or simply by clicking on a file with extension .pl). At Prolog’s prompt, type in:
?- s([the,daughter,of,the,neighbour,of,the,cousin,hates,her,aunt],[]).
true.
?- s([the, daughter,the,of,hates,aunt],[]).
false.How does this work? Each predicate, in a DCG clause, is automatically given two arguments, which represent the lexical input list and the lexical output list. So the DCG clause:
a --> b, c.is equivalent to the Prolog clause:
a(LexIn,LexOut) :-
b(LexIn,LexInt),
c(LexInt,LexOut).To verify this, execute the file containing your DCG rules and then type: listing.
If your file contains the clause a --> b, c., then somewhere in the result you should see something like:
a(A, C) :-
b(A, B),
c(B, C).The Prolog interpreter is kind enough to generate these clauses automatically for us. But we still need to provide the two arguments when using the grammar, as when we call the predicate s (see above).
Text generation
?- s(S,[]).
S = [the, dog, grumbles] ;
S = [the, dog, likes] ;
S = [the, dog, gives] ;
S = [the, dog, talks] ;
S = [the, dog, annoys] ;
S = [the, dog, hates] ;
S = [the, dog, cries] ;
S = [the, dog, grumbles, the, dog] ;
S = [the, dog, grumbles, the, daughter] ;
S = [the, dog, grumbles, the, son] ;
S = [the, dog, grumbles, the, sister] ;
S = [the, dog, grumbles, the, aunt] ;
S = [the, dog, grumbles, the, neighbour] ;
S = [the, dog, grumbles, the, cousin] ;
S = [the, dog, grumbles, my, dog] ;
S = [the, dog, grumbles, my, daughter] ;
. . .
| How many different sentences can be generated by this grammar? |
DCGs can be used to detect structural patterns such as palindromes:
pal --> c(C), pal, c(C). % central recursion
pal --> c(C), c(C). % termination for an even list
pal --> c(_). % termination for an odd list
c(C) --> [C], {member(C,[0,1,2,3,4,5,6,7,8,9])}. % Prolog code embedded in DCG using { }
?- pal([3,2,1,2,3], []).
true.Note that this programme is not reversible as such, as Prolog attempts to generate an infinite palindrome made only of zeros. But a reordering of the clauses provides the expected behaviour:
?- pal(Pal,[]).
Pal = [0] ;
Pal = [1] ;
Pal = [2] ;
Pal = [3] ;
. . .
Pal = [0, 0] ;
Pal = [1, 1] ;
Pal = [2, 2] ;
Pal = [3, 3] ;
. . .
Pal = [0, 0, 0] ;
Pal = [0, 1, 0] ;
Pal = [0, 2, 0] ;
. . .
Parsing
np --> det, n.
np --> det, n, pp.Try to replace the second rule by:
np --> det, n.
np --> np, pp.A sentence like
?- s([the,daughter,of,the,neighbour,of,the,cousin,hates,her,aunt],[]).
true.is still correctly recognized. However, Prolog will enter an endless loop when given an incorrect sentence:
?- s([daughter, the, of, hates, aunt],[]).
ERROR: Out of local stack
Exception: (1,675,221) np([daughter, the, of, hates, aunt], _4674) ?
(press 'a' to abort)
| Why is the new rule faulty (for Prolog’s default parsing)? |
np --> det, n, pp.
is not very aesthetic, not only because of its redundancy with np --> det, n., but also because it introduces a ternary rule (if we allow for ternary rules, why not n-ary rules?). One could introduce a new kind of phrase instead, called cnp (complement noun phrase). This solution is not satisfactory either from a linguistic point of view. An alternative way is to change the parsing procedure. The parsing procedure used by Prolog to analyse a sentence using DCG is the standard algorithm for executing Prolog clauses. To answer the query:np([the,dog,of,the,neighbour,of,the,cousin],[]), Prolog tries to match with the first appropriate DCG clause: np --> det, n. It fails because the resulting list is not empty. Then it tries to match with the next rule: np --> det, n, pp., but since Prolog is amnesic, it has to redo the job anew to recognize [the,dog]. Here is the (partial) trace.
?- trace.
?- np([the,dog,of,the,neighbour,of,the,cousin],[]).
Call: (6) np([the, dog, of, the, neighbour, of, the, cousin], []) ?
Call: (7) det([the, dog, of, the, neighbour, of, the, cousin], _G6055) ?
Exit: (7) det([the, dog, of, the, neighbour, of, the, cousin], [dog, of, the, neighbour, of, the, cousin]) ?
Call: (7) n([dog, of, the, neighbour, of, the, cousin], []) ? skip
Fail: (7) n([dog, of, the, neighbour, of, the, cousin], []) ?
Redo: (6) np([the, dog, of, the, neighbour, of, the, cousin], []) ?
Call: (7) det([the, dog, of, the, neighbour, of, the, cousin], _G6055) ?
Exit: (7) det([the, dog, of, the, neighbour, of, the, cousin], [dog, of, the, neighbour, of, the, cousin]) ?
Call: (7) n([dog, of, the, neighbour, of, the, cousin], _G6055) ? skip
Exit: (7) n([dog, of, the, neighbour, of, the, cousin], [of, the, neighbour, of, the, cousin]) ?
Call: (7) pp([of, the, neighbour, of, the, cousin], []) ?
. . .This is a top-down method, which proves quite inefficient in most cases, especially for "garden-path sentences", such as "Fat people eat accumulates" (where "fat" is a noun), or "The cotton clothing is usually made of grows in Mississippi." (example in French: "Mme le Maire a marié Paul et Jacques y était."). For a top-down algorithm, most sentences are like "garden-path" sentences, as parsing must backtrack in an amnesic way.
Top-down parsing
% top down recognition
:- consult('dcg2rules.pl'). % DCG to 'rule' converter: gn --> det, n. becomes rule(gn,[det,n])
:- dcg2rules('family.pl'). % performs the conversion by asserting rule(gn,[det,n])
go :-
tdr([s],[la,soeur,parle,de,sa,cousine]).
tdr(Proto, Words) :- % top-down recognition - Proto = list of non-terminals or words
match(Proto, Words, [], []). % Final success. This means that Proto = Words
tdr([X|Proto], Words) :- % top-down recognition.
rule(X, RHS), % retrieving a candidate rule that matches X
append(RHS, Proto, NewProto), % replacing X by RHS (= right-hand side)
nl, write(X),write(' --> '), write(RHS),
match(NewProto, Words, NewProto1, NewWords), % see if beginning of NewProto matches beginning of Words
tdr(NewProto1, NewWords). % lateral recursive call
% match() eliminates common elements at the front of two lists
match([X|L1], [X|L2], R1, R2) :-
!,
write('\t**** reconnu: '), write(X),
match(L1, L2, R1, R2).
match(L1, L2, L1, L2).
| Execute tdr on various sentences and observe the amnesic character of the parser.
Replace the rule gn --> det, n, gnp. by the more natural rule gn --> gn, gnp. What are the consequences on tdr’s behaviour? |
Bottom-up parsing
:- consult('dcg2rules.pl'). % DCG to 'rule' converter: np --> det, n. becomes rule(gn, [det, n])
:- dcg2rules('family.pl'). % performs the conversion by asserting rule(np, [det, n])
bup([s]). % success when one gets s after a sequence of transformations
bup(P):-
write(P), nl, get0(_),
append(Prefix, Rest, P), % P is split into three pieces
append(RHS, Suffix, Rest), % P = Prefix + RHS + Suffix (RHS = right-hand side)
rule(X, RHS), % bottom up use of rule
append(Prefix, [X|Suffix], NEWP), % RHS is replaced by X in P: NEWP = Prefix + X + Suffix
bup(NEWP). % lateral recursive call
go :-
bup([the, sister, talks, about, her, cousin]).
This program (bup.pl) uses another file, dcg2rules.pl that reads a DCG file and converts dcg rules into Prolog predicates.Load bup and execute it by typing go. to parse the sentence: the sister talks about her cousin. You have to press [return] repeatedly to see what happens (comment get0 for a smooth execution).
| At first, the program rapidly recognizes [s,pp], and then forgets pp and starts over its recognition, until it prints [s,pp] one more time. Why is it so? |
| Why does the program need to undo its recognition of pp after having reached [s,pp]? |
| Reintroduce the left-recursive clause np --> np, pp. and type go. again. Does it bring the program to loop endlessly? |
|
(be sure to have restored the program with the left-recursive rule)
Try to recognize an incorrect sentence, such as bup([the, talks, sister, about, her, cousin]).What happens? |
Unification
Checking for agreement
np(Number) --> det(Number), n(Number).
det(singular) --> [a].
det(plural) --> [many].
det(_) --> [the].
n(singular) --> [dog].
n(plural) --> [dogs].
Now you can test the new grammar.
?- np(N, [a, dog], [ ]).
N = singular.
?- np(N, [many, dogs], [ ]).
N = plural.
?- np(N, [many, dog], [ ]).
false
| Modify the rule s --> np, vp. to check for subject-verb number agreement. |
| Modify the vp --> v... rules to propagate the number feature from v up to vp. |
|
Check your grammar on:
[the, dog, hates, her, aunt] [the, dogs, hates, her, aunt] [the, dogs, hate, her, aunt] |
Pursuing the logic of agreement
v(none) --> [sleeps]. % mary sleeps
v(transitive) --> [likes]. % mary likes lisa
v(intransitive) --> [talks]. % mary talks to lisa Note: the word ‘transitive’ is used with its sense in linguistics. Transitive verbs have one direct object.
| Augment our little grammar to process argument structure with features: none, transitive, intransitive. Copy the new rules below. |
| Indicate the lexical rules for the verb knows that has an optional argument ("she knows"/"she knows Paris"). |
| Treat the case of the verb talks that may have zero, one or two indirect arguments (mary talks [to peter [about the weather]]) by introducing the feature diintransitive into the grammar. Copy the new (grammatical and lexical) rules below (new rules only). |
Semantic features
|
Show by modifying a few rules in the grammar how features such as edible or sentient can be used to constrain verb semantics.
(insert new rules only) |
| Please comment on this use of features to capture semantics (illustrate what you say with examples). |
Feature structures
np([number:sing, person:3, gender:feminine, sentience:true]) --> [mary].
n([number:sing, person:3, gender:_, sentience:true]) --> [dog].
n([number:plur, person:3, gender:neutral, sentience:false]) --> [apples].
det([number:_, person:3, gender:_, sentience:_]) --> [the].
These feature structures can be made recursive to express a constraint between a verb and its subject.
v([subj:[number:sing, person:3, gender:_, sentience:true], event:false]) --> [thinks].
v([subj:[number:sing, person:3, gender:_, sentience:_], event:true]) --> [falls].
The Prolog unification system can be used to match feature structures.
?- A = [number:sing, person:3, gender:feminine, sentience:true],
B = [number:sing, person:3, gender:G, sentience:S],
A = B.
A = [number:sing, person:3, gender:feminine, sentience:true],
B = [number:sing, person:3, gender:feminine, sentience:true],
G = feminine,
S = true.Not only are the two features found to be compatible, but Prolog provides the missing slot values.
|
Rewrite the rules:
s --> np(FS1), vp(FS2). np(FS) --> det(FS), n(FS). vp(FS) --> v(FS).to check for subject-verb agreement using the above feature structures. |
Variable-length feature structures
?- A = [number:sing, person:3, sentience:true, gender:feminine | _],
B = [number:sing, person:3 | _],
A = B.
A = [number:sing, person:3, sentience:true, gender:feminine|_G1512],
B = [number:sing, person:3, sentience:true, gender:feminine|_G1512].Now the two structures A and B match, although they don’t involve the same number of attributes. This solution only works, however, if uninstantiated features happen to be at the end of the lists. This constraint is not acceptable. We obviously need the order of attributes to be irrelevant, so that the two following structures match.
A = [sentience:true, number:sing, person:3, gender:feminine |_]
B = [person:3, number:sing | _]This programme should perform the task.
unify(FS, FS) :- !. % Let Prolog do the job if it can
unify([ Feature | R1 ], FS) :-
select(Feature, FS, FS1), % checks whether the Feature is in the list
!, % the feature has been found
unify(R1, FS1).
Test unify on A and B and observe that it is deterministic.
|
Rewrite the rule s --> np, vp. to check for subject-verb agreement with unterminated feature structures.
You will need to call unify within the rule. You can do this by inserting Prolog code within brackets { } into the rule (as shown in the palindrome example). s --> np(FS1), vp(....), {%Prolog code here}. Does your grammar work? |
Further developments
Maybe you saw the video about sentences that are hard to interprete for computers.
| What do you think about this problem, in the light of machine learning or parsing techniques? |
| Please comment on the content of this lab session, and more generally on syntactic parsing. |
Tutorials
Notes
[1]
"Chart parsing": In French, Parsage tabulaire.
Back to the main page